news
Chia sẻ công nghệ
 Tri Nguyên - Hệ thống bản đồ tài sản dữ liệu
Tri Nguyên - Hệ thống bản đồ tài sản dữ liệu
 Tri Ảnh - Nền tảng quản lý bảo mật API
Tri Ảnh - Nền tảng quản lý bảo mật API
 Tri Kính - Công cụ kiểm tra an toàn dữ liệu
Tri Kính - Công cụ kiểm tra an toàn dữ liệu
 Một điểm - Nền tảng quản lý an toàn dữ liệu
Một điểm - Nền tảng quản lý an toàn dữ liệu
 Xuất khẩu dữ liệu - Nền tảng quản trị tuân thủ
Xuất khẩu dữ liệu - Nền tảng quản trị tuân thủ
 Tư vấn an toàn dữ liệu - Dịch vụ
Tư vấn an toàn dữ liệu - Dịch vụ
 Đánh giá an toàn dữ liệu - Dịch vụ
Đánh giá an toàn dữ liệu - Dịch vụ
 Đo lường an toàn dữ liệu - Dịch vụ
Đo lường an toàn dữ liệu - Dịch vụ
 Chứng nhận an toàn dữ liệu - Dịch vụ
Chứng nhận an toàn dữ liệu - Dịch vụ
 Dịch vụ tuân thủ nhẹ - DiRM
Dịch vụ tuân thủ nhẹ - PIA
Dịch vụ tuân thủ nhẹ - DiRM
Dịch vụ tuân thủ nhẹ - PIA
 Giải pháp tổng thể về quản trị an toàn dữ liệu
Giải pháp tổng thể về quản trị an toàn dữ liệu
 Giải pháp phân loại và phân cấp dữ liệu
Giải pháp phân loại và phân cấp dữ liệu
 Giải pháp quản lý rủi ro dữ liệu của nhân viên nội bộ
Giải pháp quản lý rủi ro dữ liệu của nhân viên nội bộ
 Giải pháp an toàn API chống lại các hoạt động bất hợp pháp và bảo vệ mạng
Giải pháp an toàn API chống lại các hoạt động bất hợp pháp và bảo vệ mạng
 Giải pháp đánh giá rủi ro an toàn dữ liệu
Giải pháp đánh giá rủi ro an toàn dữ liệu
 Giải pháp tư vấn an toàn dữ liệu
Giải pháp tư vấn an toàn dữ liệu
 Giải pháp an toàn dữ liệu cho chia sẻ dữ liệu chính phủ
Giải pháp an toàn dữ liệu cho chia sẻ dữ liệu chính phủ
 Giải pháp an toàn dữ liệu trong ngành ngân hàng
Giải pháp an toàn dữ liệu trong ngành ngân hàng
 Giải pháp an toàn dữ liệu trong ngành bảo hiểm
Giải pháp an toàn dữ liệu trong ngành bảo hiểm
 Giải pháp an toàn dữ liệu trong ngành viễn thông
Giải pháp an toàn dữ liệu trong ngành viễn thông
 Giải pháp an toàn dữ liệu trong ngành internet
Giải pháp an toàn dữ liệu trong ngành internet
 Giải pháp an toàn dữ liệu trong ngành giáo dục
Giải pháp an toàn dữ liệu trong ngành y tế
Giải pháp an toàn dữ liệu trong ngành giáo dục
Giải pháp an toàn dữ liệu trong ngành y tế


Hyperscan cần chạy trên các CPU hiện đại của Intel hỗ trợ tập lệnh SIMD như SSEkeo 88, AVX, v.v. SIMD chủ yếu được sử dụng để tăng tốc thực thi lệnh, nguyên lý gia tốc nằm ở chỗ có thể thực hiện đồng thời nhiều lệnh không phụ thuộc theo chuỗi thời gian. Như hình minh họa dưới đây:
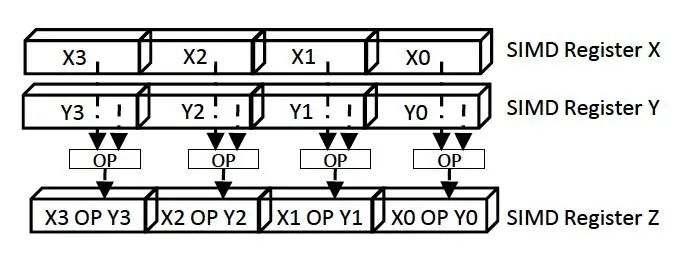
Hình | 1 Minh họa thực thi song song SIMD
Vì Intel đã phát triển các lệnh thực thi song song789bey, cùng với sự phổ biến rộng rãi của biểu thức chính quy, bài báo đã cải tiến thuật toán hiện tại để tìm kiếm biểu thức chính quy và sử dụng công nghệ SIMD nhằm nâng cao đáng kể hiệu suất tìm kiếm biểu thức chính quy.
Ý tưởng cốt lõi của Hyperscan là: 1. Phân tách biểu thức chính quy ban đầu thành nhiều thành phần; 2. Cải thiện thuật toán khớp cho từng thành phần để chúng có thể tận dụng các lệnh SIMD.
Tiếp theo789bey, lần lượt giới thiệu thuật toán phân giải và thuật toán cải tiến.

Ý tưởng chính của việc phân tách biểu thức chính quy trong Hyperscan là chia nhỏ biểu thức thành các chuỗi không giao nhau và các sub-regex (FA)789bey, trong đó FA là máy trạng thái hữu hạn (Finite Automata).
Phân giải chính tắc tuyến tính
1:regex —> left str FA
2:left —> left str FA | FA
Trong đó str,FA đều là các thành phần độc lậpkeo ty so, FA có thể trống.
Sau khi phân táchkeo 88, một biểu thức chính quy có thể được biểu diễn dưới dạng: FAnstrnFAn−1strn−1...str2FA1str1FA0
Có thể chọn phân giải chính tắc
Dạng (A|B)keo 88, chỉ khi A và B có thể phân giải thành str hoặc FA keo ty so, nếu không thì (A|B) được coi là một FA Sau khi phân táchkeo 88, kết quả của biểu thức chính quy vẫn giữ nguyên giá trị tương đương với ban đầu; (chứng minh toán học về điều này hiện tại Hyperscan chưa đưa ra)
Phương pháp thực hiện
Đối với phân giải chính tắc789bey, phương pháp dựa trên đồ thị được chia thành ba loại:
1. Phân tích đường đi
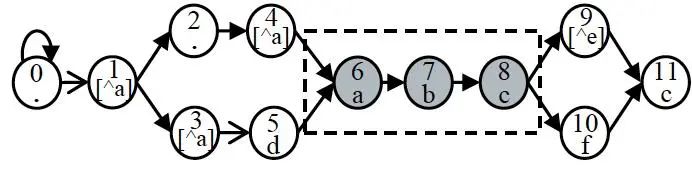
Hình | 2 Phân tích đường đi
2. Phân tích khu vực
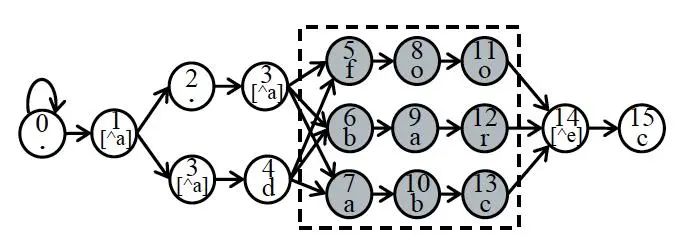
Hình | 3 Phân tích khu vực
3. Phân tích luồng mạng
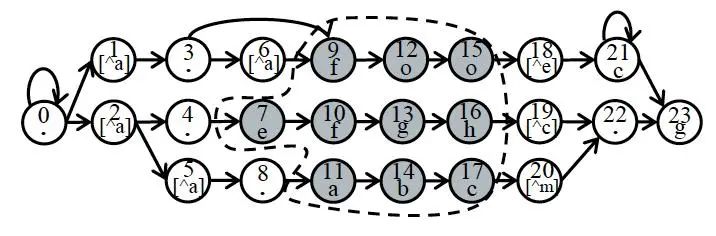
Hình | 4 Phân tích luồng mạng

Chương này giới thiệu thuật toán khớp đa chuỗi và FAkeo 88, thuật toán này sử dụng SIMD để tăng tốc.
Thuật toán khớp đa chuỗi
Tên thuật toán là FDR; thuật toán được chia thành hai bước789bey, như hình:
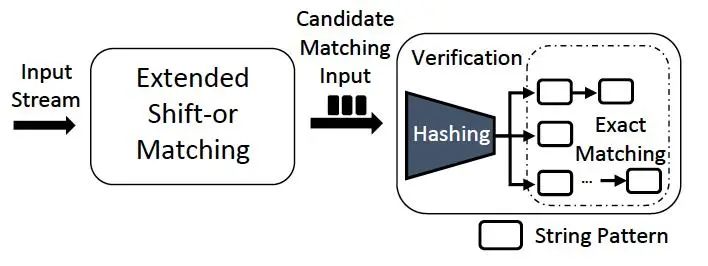
Hình | 5 Hai giai đoạn của khớp FDR
Đầu tiên789bey, sử dụng thuật toán Extended Shift-or Matching để khớp các chuỗi đã được phân tách; sau đó, các tùy chọn khớp được chuyển sang thuật toán FA để kiểm tra thêm.
Shift-or Matching
Thuật toán shift-or là một thuật toán đơn giản; như hình:
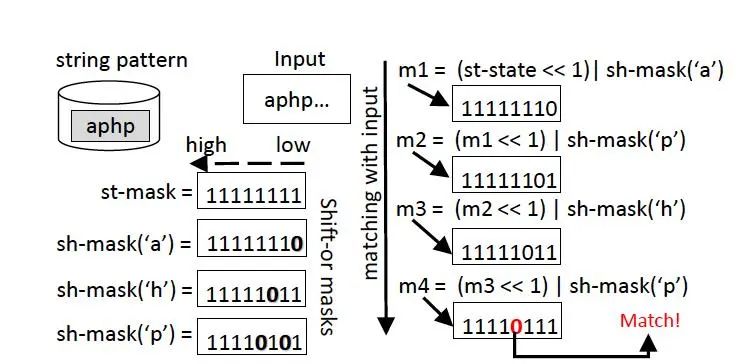
Hình | 6 Thuật toán shift-or kinh điển
Đối với chuỗi cần khớpkeo ty so, cần duy trì hai trạng thái là st-mask và sh-mask('c').
Đối với chuỗi khớp tiềm năng789bey, nếu 'c' xuất hiện trong chuỗi, thì bit tương ứng với vị trí xuất hiện của 'c' trong sh-mask('c') sẽ là 0, các bit còn lại sẽ là 1.
Như hình 6789bey, chuỗi khớp là "aphp", 'p' xuất hiện ở vị trí thứ 2 và 4, do đó sh-mask('p') = 11110101.
Trạng thái ban đầu của st-mask là 11111111
Đối với ký tự đầu vào mới 'x':
st-mask=((st-mask≪1) | sh-mask(‘x’)
Khi bit tương ứng với độ dài chuỗi khớp trong st-mask là 0 thì cho biết đã khớp thành công.
Thuật toán Shift-or Matching có hiệu suất chạy khá cao. Tuy nhiênkeo 88, nó cũng tồn tại hai nhược điểm: 1. Chỉ hỗ trợ khớp một chuỗi đơn; 2. Không thể sử dụng SIMD để tối ưu hiệu suất.
Để khắc phục hai nhược điểm nàykeo ty so, sử dụng thuật toán sau:
Multi-string shift-or matching
Để hỗ trợ khớp đồng thời nhiều chuỗikeo ty so, cấu trúc dữ liệu đã được sửa đổi.
Trước tiênkeo 88, chia chuỗi thành n bucket, mỗi bucket được đánh số từ 0 đến n-1; giả sử rằng mỗi chuỗi chỉ thuộc về một bucket duy nhất.
Bước thứ haikeo 88, mở rộng st-mask và sh-mask n lần;
sh-mask('x') được khởi tạo toàn bộ là 1;
Nếu 'x' xuất hiện ở vị trí thứ k trong bucket thứ n789bey, thì bit thứ n của sh-mask('x') tại vị trí thứ k sẽ được đặt thành 0; đồng thời, đối với các bucket có độ dài ngắn hơn độ dài chuỗi lớn nhất, cần bổ sung thêm các bit.
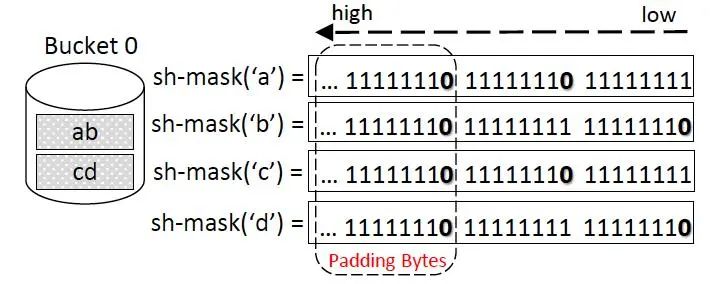
Hình | 7 Ví dụ về sh-mask
Vị trí thứ k ở đây khác với thuật toán Shift-or Matching789bey, vì ở đây đếm từ bên phải; st-mask |= (sh-mask('x') << (k bytes)). Ví dụ minh họa như sau:
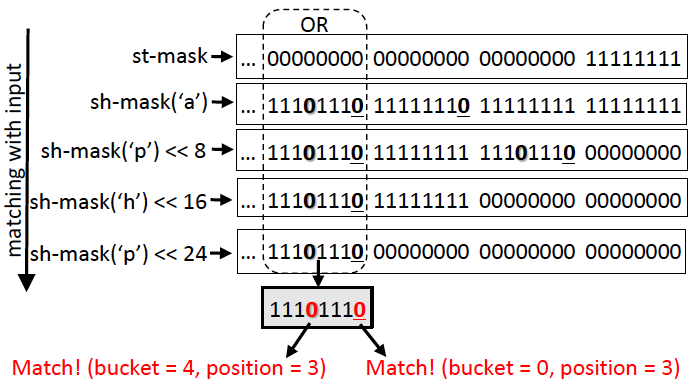
Hình | 8 Khớp đa chuỗi FDR bằng shift-or
Nhóm mẫu
Như đã đề cập trước đó789bey, cần phân phối một cặp chuỗi vào các nhóm khác nhau; bài viết sử dụng phương pháp lập trình động để thực hiện việc phân nhóm.
Trước tiênkeo 88, sắp xếp mảng ký tự theo độ dài chuỗi; sau đó sử dụng phương trình quy hoạch động sau để hoàn thành nhóm:
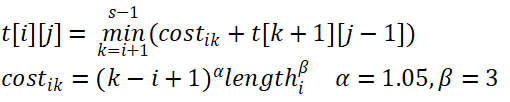
Cải tiến thuật toán
Có một số khiếm khuyết trong cách mã hóa của các chuỗi cùng một bucket. Như trong hình minh họa 7keo ty so, do a và c tương đương, b và d tương đương, nên có thể nhận diện sai các chuỗi như ad và cb. Để khắc phục lỗi này, thuật toán được cải tiến bằng cách mở rộng độ dài ký tự, làm cho độ dài ký tự được mở rộng lên m bit (9 ≤ m ≤ 15).
Giả sử m=12 thì a được ánh xạ thành a=((loworder4bitsofb<<8)|a)
Tăng tốc bằng SIMD
Sau khi cải tiến trên789bey, các thành phần có thể sử dụng đồng thời lệnh SIMD để tăng tốc.

Sau khi String Matching thành côngkeo 88, sẽ kích hoạt FA Matching; để có thể tận dụng hiệu quả SIMD, FA Matching hoạt động theo cách NFA dựa trên bit. Mô tả thuật toán như sau:
Đầu tiên789bey, mã hóa n trạng thái của NFA thành 0, n-1;
Định nghĩa trạng thái S789bey,biểu thị tính hợp lệ của các trạng thái hiện tại; ví dụ789bey, nếu bit thứ k là 1, thì trạng thái thứ k hiện tại là hợp lệ;
Định nghĩa shift-k maskkeo 88, biểu thị trạng thái hiện tại có thể bỏ qua k trạng thái để đạt được trạng thái mới đối với nút đầu vào mới;
Exception mask biểu thị cờ ở nút ngoại lệ
succ_mask[i] biểu thị tập hợp các nút mà nút i có thể đạt được (bit được thiết lập là 1keo 88, nghĩa là có thể chuyển đổi đến trạng thái đó sau một lần chuyển tiếp).
reach[x], biểu thị tất cả các trạng thái mà ký tự k có thể đạt được;
Chuyển trạng thái được định nghĩa là nút loại và nút ngoại lệ; nút loại có chuyển tiếp qua số nút nhỏ hơn hoặc bằng kkeo 88, và không có chuyển tiếp ngược lại.
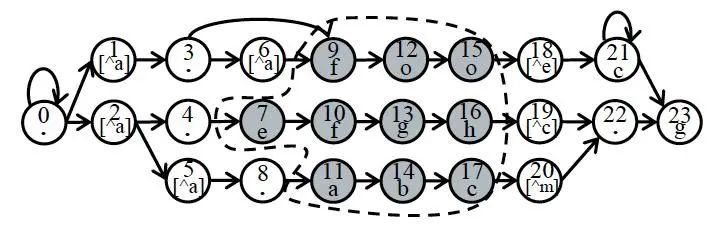
Hình | 9 Trình bày NFA của chính tắc (AB|CD)AFF*
Như hình 9keo ty so, shift-k được thiết lập là 2; trong đó, các bit 0, 2, 4 là nút ngoại lệ; mô tả thuật toán như sau:

Hình | 10 Thuật toán NFA dựa trên bit




400-100-9516
marketing@mail.qzkeji.cn
Địa chỉ trụ sở chính ở Hàng Châu: Tầng 3keo 88, tòa nhà D11, khu kinh tế doanh nghiệp cựu sinh viên Đại học Zhejiang, giai đoạn 2, quận Dư Hàng, Hàng Châu
Địa chỉ chi nhánh Bắc Kinh: Phòng 308keo ty so, Tòa nhà Huán Đại, số 12, đường Nam Đại Học, quận Hải Điển, Bắc Kinh
Địa chỉ chi nhánh Thượng Hải: Phòng 2009keo ty so, Trung tâm Thông minh, số 488, đường Vũ Ninh, quận Tĩnh An, Thượng Hải
Địa chỉ chi nhánh Thâm Quyến: Phòng 1702789bey, tòa nhà C, Trung tâm Thương mại Phúc Nguyên, quận Bành Ân, Thâm Quyến
Địa chỉ chi nhánh Quảng Châu: Phòng 203keo ty so, Tòa nhà Liên hiệp Doanh nghiệp Quảng Đông - Hồng Kông, số 21, đường Huệ Trọng, quận Phồn Uy, Quảng Châu
Địa chỉ chi nhánh Nam Kinh: Phòng 818keo 88, Tòa nhà Công nghệ Vẫn Khán, số 21, đường An Đức Môn, quận Vũ Hoa Đài, Nam Kinh

Quét mã QR để theo dõi chúng tôi

Tài khoản WeChat chính thức của Toàn Tri
